Роутинг что это
Маршрутизация — что это такое и как работает
23 ноября, 2019
Автор: Maksim
Практически каждый пользователь интернета, который читал материалы на тему работы глобальной паутины и ее нюансах в целом слышали про маршрутизацию и, некоторые в какой-то степени даже понимают, что это.
Но, это довольно интересная тема и я решил вынести ее в отдельную статью, давайте узнаем, что это такое, как она работает, зачем она вообще нужна и какие у нее бывают виды. На самом деле это все довольно просто.
Итак, вы уже знаете, что такое UDP протокол и зачем он нужен, сейчас же мы разберем не менее интересную тему о том, как строятся пути для передачи информации в IP сетях.
Что такое маршрутизация
Маршрутизация (Routing) — это процесс по определению/вычислению лучшего маршрута движения для данных в сетях связи. Есть еще второе определение — это передача пакетов данных от отправителя к получателю.
Сами маршруты могут быть статическими — задаются административно, или динамическими, т.е. рассчитываться по специальным алгоритмам-протоколам, которые базируются на данных о топологии и состоянии сети.
Функцию роутинга могут выполнять:
- Аппаратные средства — маршрутизаторы. Самый оптимальный вариант, позволяющий обрабатывать большие потоки данных и работает он быстрее.
- Настроенные компьютеры с несколькими сетевыми интерфейсами и установленным на них специализированным и настроенным ПО. Обычно используется если конфигурация будет не слишком сложная.
Таблица маршрутизации
Таблица маршрутизации — это файл-электронная таблица или база данных, которая располагается на маршрутизаторе или специально настроенном компьютере. В ней описывается соответствие адресов назначения с интерфейсами, через которые необходимо производить отправку данных до следующего маршрутизатора.
Таблица содержит:
- Адрес сети или узла
- Маску подсети назначения
- Сетевой шлюз или по-другому, адрес маршрутизатора на который будут направлены данные
- Интерфейс, с которого можно достучаться до шлюза
- Метрика (не всегда), т.е. показатель, который задает предпочтительность пути.
Может заполняться как вручную, так и автоматически.
Протокол маршрутизации
Протокол маршрутизации используется маршрутизаторами для определения возможных и оптимальных маршрутов движения пакетов данных по сети. Текущий протокол позволяет обеспечивать маршрут на автоматическом уровне избегая ручного ввода.
Это в свою очередь снижает возможное количество ошибок, делает взаимодействие всех роутеров в сети согласованным и, конечно же, облегчает работу самому администратору.
Маршрутизация в IP сетях
По итогу, все это нужно для отправки и приема пакетов данных от одного устройства по сетке к другому и это может происходить через разные сети. Сами маршрутизаторы/роутеры отправляют данные практически во все сети, из локальной в глобальную паутину, используют NAT и т.д.
Информация на роутер поступает от других таких-же роутеров или от администратора. Составляется таблица — вручную или динамически. И, соответственно, пакеты данных отправляются.
Виды
Статическая маршрутизация
В данном случае маршруты задаются в таблице напрямую администратором во время конфигурации маршрутизатора, без использования протоколов, помогающих построить пути.
При задании такого маршрута назначается:
- Адрес и маска сети
- Адрес шлюза/узла
- Иногда указывается метрика и интерфейс, на который пойдет трафик
Плюсы:
- Легкость настройки в не крупных сетках
- Небольшая нагрузка на саму сетку, что в какой-то степени увеличивает скорость интернета
- Прозрачность работы в любой момент времени
- Не требует дополнительных денежных расходов, т.к. не используются протоколы построения путей
Минусы:
- Долгое масштабирование, каждая добавленная сетка потребует двойных вмешательств в конфигурацию
- Если произошли какие-либо изменения, то в любом случае администратору придется вручную настраивать новые пути
- Нет динамического балансирования нагрузки
- Нужна отдельная документация с записями маршрутов, также, проблемы с синхронизацией этой документации и реальных путей
Динамическая маршрутизация
В этом случае таблица редактируется на программном уровне и рассчитывается по протоколам. Позволяет маршрутизаторам в реальном времени своевременно менять пути, применяемые для передачи IP пакетов. У каждого протокола есть свой метод определения маршрута движения пакетов: самый быстрый путь, использование именно того маршрута, который рекомендуют другие роутеры и т.д.
Так, если в сети произойдут какие-либо изменения, то протокол динамической маршрутизации оповестит об этом все маршрутизаторы, а вот при статической, все придется делать администратору.
В заключение
Работая в интернете или читая там занимательную литературу, вы даже не замечаете сколько процессов происходит, а происходит там очень много. Если вам и дальше интересны материалы на темы работы интернета, то заходите еще.
Routes. The Beginning / Хабр
Роуты в рельсах очень важная вещь. Но до поры до времени можно даже не обращать внимание на них. Особенно если вы пользуетесь командой scaffold, которая автоматически все прописывает. Но в какой-то момент появляется необходимость создавать нестандартные роуты. Это значит самое время залезать в файл routes.rb в папке config вашего проекта.Роуты — это система маршрутов (путей, url'ов) на вашем сайте. Благодаря роутам мы можем иметь красивые и ясные для пользователей ссылки. Введя ссылку вроде mysite.ru/articles/2008/november/13 мы получим все статьи за 13 ноября 2008 года, а по ссылке mysite.ru/shop/shoes получим каталог обуви из вашего магазина. При всем при этом, структура каталогов сайта никак не изменяется. В любой момент мы можем изменить роуты не трогая расположение самих файлов. Но чтобы все это работало нам необходимо настроить роуты.
Давайте создадим тестовый проект, с которым мы будем шаманить. (Если вы это делает впервые, то можно обсудить в комментариях процесс установки рельс и создания приложения).
rails routes
cd routes
Окей. Проект создан и мы вошли в рабочую папку. Сразу набросимся на роуты:
rake routes
эта команда вам выдаст две строчки стандартных роутов./:controller/:action/:id
/:controller/:action/:id.:format
Это значит, что любой урл сейчас будет парситься по этим двум правилам.
:controller — это Контроллер =). Это компонент MVC, который чаще всего выступает как посредник между Представлением (HTML) и Моделью (база данных, скажем). Дальше будет яснее, но скорее всего вы итак знаете, что это такое.
:action — это вызываемый метод контроллера. У контроллера обычно много методов.
:id — если я вно не указывать запрет на создание id, то по умолчанию любая модель (таблица БД) создается с полем id. Поэтому любой элемент модели имеет id. И когда вы хотите удалить/редактировать/что угодно делать с каким-то конкретным элементом модели вы обязаны передать в контроллер этот самый id.
Окей. Давайте мы создадим новостной журнал. Для этого нам нужны:
— Таблица news в нашей базе данных (Модель). В БД мы будем хранить заголовок статьи (title), автора статьи (author) и собственно саму статью (article)
— Набор методов для работы с БД (Контроллер)
— HTML формы для ввода, редактирования, чтения новостей (Представление)
Мы можем создавать все это по отдельности. Но сейчас мы упростим себе задачу и используем функцию scaffold для генерации пачки готовых файлов.
./script/generate scaffold Magazine title:string author:string article:text
Мы только что создали все выше перечисленное (а также Helpers, о которых как-нибудь в другой раз). Также команда scaffold сама создала необходимые роуты. Еще раз наберите команду rake routes и вывалится кипа новых роутов
magazines GET /magazines {:controller=>"magazines", :action=>"index"} formatted_magazines GET /magazines.:format {:controller=>"magazines", :action=>"index"} POST /magazines {:controller=>"magazines", :action=>"create"} POST /magazines.:format {:controller=>"magazines", :action=>"create"} new_magazine GET /magazines/new {:controller=>"magazines", :action=>"new"} formatted_new_magazine GET /magazines/new.:format {:controller=>"magazines", :action=>"new"} edit_magazine GET /magazines/:id/edit {:controller=>"magazines", :action=>"edit"} formatted_edit_magazine GET /magazines/:id/edit.:format {:controller=>"magazines", :action=>"edit"} magazine GET /magazines/:id {:controller=>"magazines", :action=>"show"} formatted_magazine GET /magazines/:id.:format {:controller=>"magazines", :action=>"show"} PUT /magazines/:id {:controller=>"magazines", :action=>"update"} PUT /magazines/:id.:format {:controller=>"magazines", :action=>"update"} DELETE /magazines/:id {:controller=>"magazines", :action=>"destroy"} DELETE /magazines/:id.:format {:controller=>"magazines", :action=>"destroy"} Теперь мы запустим сервер и поиграемся с журналом. Но сперва мы создадим нашу базу данных и запустим миграции.
rake db:create
rake db:migrate
./script/server
Наш журнал теперь доступен по адресу localhost:3000/magazines
Создайте пару новых статей.
Вернемся к таблице роутов выше. Первый столбец — это именные роуты. Они очень удобны. Есть несколько вариантов сейчас сделать ссылку на создание новой статьи. Откройте файл app/views/magazines/index.html.erb — это представление для метода index в контроллере magazines_controller.
В самом низу давайте допишем немного кода.
<hr> <%= link_to 'Новая статья', :action => 'new' %><br /> <%= link_to 'Новая статья', '/magazines/new' %><br /> <%= link_to 'Новая статья', new_magazine_path %><br /> <%= link_to 'Новая статья', new_magazine_url %><br />
Самым правильным будет использование последних двух методов. Разница в том, что url возвращает полную ссылку (http://localhost:3000/magazines/new), а path только путь (/magazines/new). Почему лучше пользоваться именными роутами? Именной роут это переменная, изменив которую вы меняете все ссылки, которые пользуются этим роутом. Писать пути от руки вобще не рекомендуется, если приспичило, то лучше написать :action => 'new' (зачастую именных роутов на все случаи жизне не хватает, поэтому этот вариант очень распространен).
Второй столбец таблицы — это метод запроса. Одна и таже ссылка, но с разным методом ведет на разные методы контроллера. К примеру, в том же app/views/magazines/index.html.erb:<%= link_to 'Show', magazine %>
<%= link_to 'Destroy', magazine, :method => :delete %>
В первой ссылке исполняется дефолтный GET запрос (можно не указывать в ссылке :method=>:get), а во второй отправляется метод :delete. А ссылка magazine остается в обоих случаях одинаковая.
Третий столюбец — это собственно ссылки, которые мы получим в HTML. Последний столбец — это соответствие ссылок контроллеру и методу. Как уже выше писалось, любую ссылку можно представить в виде пары :controller, :action (ну и иногда :method).
<%= link_to 'Ссылка на другой контроллер из контроллера magazines', :controller => 'blogs', :action=>'show', :id=>'1', :method=>'GET' %>
Так мы получим ссылку на блог с индексом 1. (Тут метод :get можно было и не указывать)
<%= link_to 'Ссылка на родной метод контроллера', :action => 'show', :id => '1' %>
Ссылка на статью с индексом 1. Контроллер и HTTP метод в данном случае указывать не надо, так как GET исполняется по умолчанию, а контроллер, если не указан, выполняется тот же.
Тепрь откройте файл config/routes.rb (можете удалить весь закомментированный текст)
map.resources :magazines
map.connect ':controller/:action/:id'
map.connect ':controller/:action/:id.:format'
Первую строчку вставила команда scaffold. Эта строчка и добавила нам пачку роутов, которую мы наблюдали выше.
Если вы сейчас наберете просто localhost:3000 вы попадете на приветственную страницу. Давайте это исправим.
map.root :controller => 'magazines'
Теперь из папки public удалите index.html и зайдя на localhost:3000 вы попадете напрямую куда надо =). Кроме того если вы просмотрите все роуты занова (rake routes), то увидите новый именной роут root. И в меню сможете сделать ссылку на «Главную» вида:
<%= link_to 'Главная', root %>
И вы всегда без ущерба ссылкам сможете изменить домашнюю страницу, скажем, на ваш магазин map.root :controller => 'shop'
Собственно создав root вы создали первый именной роут своими руками.
Давайте создадим именной роут «localhost:3000/zhurnal». Не хотим мы буржуйский 'magazines', хотим 'zhurnal'!
map.zhurnal '/klevi_zhurnal/:id', :controller => 'magazines', :id => nil
Итак, мы создали именной роут zhurnal, урл которого будет выглядеть как localhost:3000/klevi_zhurnal, а контент он будет получать от контроллера magazines. Если мы попробуем прочесть статью теперь вроде localhost:3000/klevi_zhurnal/1 — то мы обламаемся. Внесем в наш роут немного изменений:
map.zhurnal '/klevi_zhurnal/:action/:id', :controller => 'magazines', :action => 'index', :id => nil
Что все это значит:
— урл вида /klevi_zhurnal/ будет отработан :controller => 'magazines', :action => 'index', :id => 'nil' — то есть мы получим индексовую страницу (index.html.erb)
— /klevi_zhurnal/1 выплюнет ошибку, что action '1' не существует (посмотрите на последовательность передачи аргумента в роуте)
— /klevi_zhurnal/show скажет, что ID не указано
— /klevi_zhurnal/show/1 — выдаст вам статью с ID=1 (если она конечно существует)
— /klevi_zhurnal/edit/1 — выдаст форму редактирования этой статьи
Правда теперь несколько тяжелее выглядят сами ссылки:
Вместо <%= link_to 'Все статьи', magazines_path %> будет <%= link_to 'Все статьи', zhurnal_path %>
Вместо <%= link_to 'Статья номер 1', magazine_path('1') %> будет <%= link_to 'Статья номер 1', zhurnal_path(:action=>'show', :id=>'1') %>
Обратите внимание на то, что для лучшего понимания роутов введена система множественного/единственного числа:
показать все статьи magazines_path,
показать отдельную статью: magazine_path.
Чорт — не самое правильное слово вообще выбрал =). Если бы у нас все называлось Article:
index => articles_path, show => article_path(:id)
Теперь давайте создадим новый метод.
Откройте app/controllers/magazines_controller.rb
Добавьте туда метод
def random
offset = rand(Magazine.count :all)
@magazine = Magazine.find(:first, :offset => offset)
render :action => 'show'
end
Этот метод просто возвращает рандомно статью. Давайте попробуем его вызвать: localhost:3000/magazines/random
Получаем ошибку — требует от нас ID. Почему? Потому что стандартный роут продразумевает роут вида :controller/:action/:id.
Давайте попробуем вызвать роут по правилам:
localhost:3000/magazines/random/1230492
Записи с таким ID не существует — но все работает! Так как мы в нашем методе не используем ID вообще — то для нас и не принципиально какую ерунду мы там напишем.
Давайте теперь все же попробуем сделать корректный роут вида localhost:3000/magazines/random/
Для этого существует опция :collection => { :action => :HTTP_method }
Наш :action это :random, метод — :get
получаем
map.resources :magazines, :collection => { :random => :get }
теперь все работает! =)
На этом вводная часть заканчивается. Дальше нас ждут более изощренные методы извращения ). Но не сегодня.
Спасибо, за потраченное на чтение статьи время ).
API для желающих
Скринкасты Райана Бейтса
Роутинг и policy-routing в Linux при помощи iproute2 / Хабр
Речь в статье пойдет о роутинге сетевых пакетов в Linux. А конкретно – о типе роутинга под названием policy-routing (роутинг на основании политик). Этот тип роутинга позволяет маршрутизировать пакеты на основании ряда достаточно гибких правил, в отличие от классического механизма маршрутизации destination-routing (роутинг на основании адреса назначения). Policy-routing применяется в случае наличия нескольких сетевых интерфейсов и необходимости отправлять определенные пакеты на определенный интерфейс, причем пакеты определяются не по адресу назначения или не только по адресу назначения. Например, policy-routing может использоваться для: балансировки трафика между несколькими внешними каналами (аплинками), обеспечения доступа к серверу в случае нескольких аплинков, при необходимости отправлять пакеты с разных внутренних адресов через разные внешние интерфейсы, даже для отправки пакетов на разные TCP-порты через разные интерфейсы и т.д.Для управления сетевыми интерфейсами, маршрутизацией и шейпированием в Linux служит пакет утилит iproute2.
Этот набор утилит лишь задает настройки, реально вся работа выполняется ядром Linux. Для поддержки ядром policy-routing оно должно быть собрано с включенными опциями IP: advanced router (CONFIG_IP_ADVANCED_ROUTER) и IP: policy routing (CONFIG_IP_MULTIPLE_TABLES), находящимися в разделе Networking support -> Networking options -> TCP/IP networking.
ip route
Для настройки роутинга служит команда ip route. Выполненная без параметров, она покажет список текущих правил маршрутизации (не все правила, об этом чуть позже):
# ip route 192.168.12.0/24 dev eth0 proto kernel scope link src 192.168.12.101 default via 192.168.12.1 dev eth0
Так будет выглядеть роутинг при использовании на интерфейсе eth0 IP-адреса 192.168.12.101 с маской подсети 255.255.255.0 и шлюзом по умолчанию 192.168.12.1.
Мы видим, что трафик на подсеть 192.168.12.0/24 уходит через интерфейс eth0.
proto kernel означает, что роутинг был задан ядром автоматически при задании IP интерфейса. scope link означает, что эта запись является действительной только для этого интерфейса (eth0). src 192.168.12.101 задает IP-адрес отправителя для пакетов, попадающих под это правило роутинга.Трафик на любые другие хосты, не попадающие в подсеть 192.168.12.0/24 будет уходить на шлюз 192.168.12.1 через интерфейс eth0 (
default via 192.168.12.1 dev eth0). Кстати, при отправке пакетов на шлюз, IP-адрес назначения не изменяется, просто в Ethernet-фрейме в качестве MAC-адреса получателя будет указан MAC-адрес шлюза (часто даже специалисты со стажем путаются в этом моменте). Шлюз в свою очередь меняет IP-адрес отправителя, если используется NAT, либо просто отправляет пакет дальше. В данном случае используются приватный адрес (192.168.12.101), так что шлюз скорее всего делает NAT.А теперь залезем в роутинг поглубже. На самом деле, таблиц маршрутизации несколько, а также можно создавать свои таблицы маршрутизации. Изначально предопределены таблицы local, main и default. В таблицу local ядро заносит записи для локальных IP адресов (чтобы трафик на эти IP-адреса оставался локальным и не пытался уходить во внешнюю сеть), а также для бродкастов. Таблица main является основной и именно она используется, если в команде не указано какую таблицу использовать (т.е. выше мы видели именно таблицу main). Таблица default изначально пуста. Давайте бегло взглянем на содержимое таблицы local:
# ip route show table local broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1 broadcast 192.168.12.255 dev eth0 proto kernel scope link src 192.168.12.101 broadcast 192.168.12.0 dev eth0 proto kernel scope link src 192.168.12.101 local 192.168.12.101 dev eth0 proto kernel scope host src 192.168.12.101 broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1 local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1 local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
broadcast и local определяют типы записей (выше мы рассматривали тип default). Тип broadcast означает, что пакеты соответствующие этой записи будут отправлены как broadcast-пакеты, в соответствии с настройками интерфейса. local – пакеты будут отправлены локально. scope host указывает, что эта запись действительная только для этого хоста.Для просмотра содержимого конкретной таблицы используется команда
ip route show table TABLE_NAME. Для просмотра содержимого всех таблиц в качестве TABLE_NAME следует указывать all, unspec или 0. Все таблицы на самом деле имеют цифровые идентификаторы, их символьные имена задаются в файле /etc/iproute2/rt_tables и используются лишь для удобства.ip rule
Как же ядро выбирает, в какую таблицу отправлять пакеты? Все логично – для этого есть правила. В нашем случае:
# ip rule 0: from all lookup local 32766: from all lookup main 32767: from all lookup default
Число в начале строки – идентификатор правила,
from all – условие, означает пакеты с любых адресов, lookup указывает в какую таблицу направлять пакет. Если пакет подпадает под несколько правил, то он проходит их все по порядку возрастания идентификатора. Конечно, если пакет подпадет под какую-либо запись маршрутизации, то последующие записи маршрутизации и последующие правила он уже проходить не будет.Возможные условия:
from– мы уже рассматривали выше, это проверка отправителя пакета.to– получатель пакета.iif– имя интерфейса, на который пришел пакет.oif– имя интерфейса, с которого уходит пакет. Это условие действует только для пакетов, исходящих из локальных сокетов, привязанных к конкретному интерфейсу.tos– значение поля TOS IP-пакета.fwmark– проверка значения FWMARK пакета. Это условие дает потрясающую гибкость правил. При помощи правилiptablesможно отфильтровать пакеты по огромному количеству признаков и установить определенные значения FWMARK. А затем эти значения учитывать при роутинге.
Условия можно комбинировать, например
from 192.168.1.0/24 to 10.0.0.0/8, а также можно использовать префикc not, который указывает, что пакет не должен соответствовать условию, чтобы подпадать под это правило.Итак, мы разобрались что такое таблицы маршрутизации и правила маршрутизации. А создание собственных таблиц и правил маршрутизации это и есть policy-routing, он же PBR (policy based routing). Кстати SBR (source based routing) или source-routing в Linux является частным случаем policy-routing, это использование условия
from в правиле маршрутизации.Простой пример
Теперь рассмотрим простой пример. У нас есть некий шлюз, на него приходят пакеты с IP 192.168.1.20. Пакеты с этого IP нужно отправлять на шлюз 10.1.0.1. Чтобы это реализовать делаем следующее:
Создаем таблицу с единственным правилом:
# ip route add default via 10.1.0.1 table 120
Создаем правило, отправляющее нужные пакеты в нужную таблицу:
# ip rule add from 192.168.1.20 table 120
Как видите, все просто.
Доступность сервера через несколько аплинков
Теперь более реалистичный пример. Имеется два аплинка до двух провайдеров, необходимо обеспечить доступность сервера с обоих каналов:

В качестве маршрута по умолчанию используется один из провайдеров, не важно какой. При этом веб-сервер будет доступен только через сеть этого провайдера. Запросы через сеть другого провайдера приходить будут, но ответные пакеты будут уходить на шлюз по умолчанию и ничего из этого не выйдет.
Решается это весьма просто:
Определяем таблицы:
# ip route add default via 11.22.33.1 table 101 # ip route add default via 55.66.77.1 table 102
Определяем правила:
# ip rule add from 11.22.33.44 table 101 # ip rule add from 55.66.77.88 table 102
Думаю теперь уже объяснять смысл этих строк не надо. Аналогичным образом можно сделать доступность сервера по более чем двум аплинкам.
Балансировка трафика между аплинками
Делается одной элегантной командой:
# ip route replace default scope global \ nexthop via 11.22.33.1 dev eth0 weight 1 \ nexthop via 55.66.77.1 dev eth2 weight 1
Эта запись заменит существующий default-роутинг в таблице main. При этом маршрут будет выбираться в зависимости от веса шлюза (
weight). Например, при указании весов 7 и 3, через первый шлюз будет уходить 70% соединений, а через второй – 30%. Есть один момент, который при этом надо учитывать: ядро кэширует маршруты, и маршрут для какого-либо хоста через определенный шлюз будет висеть в таблице еще некоторое время после последнего обращения к этой записи. А маршрут до часто используемых хостов может не успевать сбрасываться и будет все время обновляться в кэше, оставаясь на одном и том же шлюзе. Если это проблема, то можно иногда очищать кэш вручную командой ip route flush cache.Использование маркировки пакетов при помощи iptables
Допустим нам нужно, чтобы пакеты на 80 порт уходили только через 11.22.33.1. Для этого делаем следующее:
# iptables -t mangle -A OUTPUT -p tcp -m tcp --dport 80 -j MARK --set-mark 0x2 # ip route add default via 11.22.33.1 dev eth0 table 102 # ip rule add fwmark 0x2/0x2 lookup 102
Первой командой маркируем все пакеты, идущие на 80 порт. Второй командой создаем таблицу маршрутизации. Третьей командой заворачиваем все пакеты с указанной маркировкой в нужную таблицу.
Опять же все просто. Рассмотрим также использование модуля iptables CONNMARK. Он позволяет отслеживать и маркировать все пакеты, относящиеся к определенному соединению. Например, можно маркировать пакеты по определенному признаку еще в цепочке INPUT, а затем автоматически маркировать пакеты, относящиеся к этим соединениям и в цепочке OUTPUT. Используется он так:
# iptables -t mangle -A INPUT -i eth0 -j CONNMARK --set-mark 0x2 # iptables -t mangle -A INPUT -i eth2 -j CONNMARK --set-mark 0x4 # iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
Пакеты, приходящие с eth0 маркируются 2, а с eth2 – 4 (строки 1 и 2). Правило на третьей строке проверяет принадлежность пакета к тому или иному соединению и восстанавливает маркировки (которые были заданы для входящих) для исходящих пакетов.
Надеюсь изложенный материал поможет вам оценить всю гибкость роутинга в Linux. Спасибо за внимание :)
Делаем маршрутизацию (роутинг) на OpenStreetMap. Введение / Хабр
Хотелось бы поделиться опытом создания систем маршрутизации PostgreSQL/PgRouting на карте OpenStreetMap. Речь пойдет о разработке [коммерческих] решений со сложными требованиями, для более простых проектов, вероятно, достаточно обратиться к документации. Насколько мне известно, такие вещи, как полная поддержка односторонних дорог и направлений движения, быстрый роутинг на тысячах адресов (порядка секунд на обычном лаптопе, к примеру, Macbook Pro 13" 2013 года), создание дорожного графа с заданными свойствами, мета-оптимизация маршрутов вообще нигде и никак не рассматриваются. Как обычно, все данные и результаты доступны в моем GitHub репозитории OSM Routing Tricks, который я буду пополнять по мере публикаций.
Небольшой маршрут из 330 адресов на карте OpenStreetMap (время построения около 5 секунд на вышеупомянутом лаптопе). Можно ли за это же время построить маршрут, скажем, из 5000 точек? Да, можно, и об этом мы тоже поговорим (в следующих частях статьи).
Что такое маршрутизация и зачем она нужна
Пожалуй, легче сказать, где маршрутизация не используется, чем перечислить все ее применения. Например: маршрутизация нужна для доступа к этой статье в сети интернет, для доставки почты или посылок, для путешествий, и даже для спутниковой интерферометрии, о которой я писал ранее, тоже используется маршрутизация (вычисление суммарного сдвига фазы по замкнутым траекториям на растре)! Далее мы будем говорить только о применении расширения PgRouting для СУБД PostgreSQL и карте OpenStreetMap.
В идеале, для поиска оптимального маршрута нам нужно рассмотреть все возможные комбинации из входящих в него адресов. На практике, очевидно, сделать это не удастся для сколько-нибудь значительного количества адресов и потому используются разные приближенные методы. В частности, в расширении PgRouting для поиска оптимального маршрута используется алгоритм отжига. Как и у других методов, у него есть свои преимущества и недостатки, поэтому мы будем обсуждать именно такую реализацию, хотя все или почти все сказанное применимо и к другим методам приближенного поиска оптимального маршрута.
Очень рекомендую также ознакомиться с соответствующей статьей википедии Задача коммивояжёра, поскольку многие старые подходы к задаче и сейчас успешно используются в качестве оптимизаций и решений для частных случаев.
Версии программ и операционные системы
Для новых проектов рекомендую актуальную версию PgRouting 3.0 и СУБД PostgreSQL 12, хотя тот же код обычно работает с PgRouting 2.6 и СУБД PostgreSQL 9 и более давними. Стоит отметить, что на MacOS (любой версии) и Debian/Ubuntu (любой версии) результаты работы функции PgRouting для поиска оптимального маршрута pgr_TSP() сильно отличаются, при этом, как правило, на линуксах результаты при параметрах по умолчанию получаются значительно лучше, при этом используемый алгоритм "отжига" в компиляции на MacOS работает нестабильно, то есть небольшие изменения параметров приводят к непредсказуемым изменениям результатов при недостаточно продуманном дорожном графе, что, кстати сказать, очень помогает при тестировании. Сам я использую и MacOS и Debian/Ubuntu.
Как загрузить OpenStreetMap в базу данных PostgreSQL
Существует много разных утилит, из которых я предпочитаю GDAL, на мой взгляд, наиболее мощную и предсказуемую. Эта утилита позволяет, в частности, преобразовать дамп OpenStreetMap в дамп PostgreSQL и потом загрузить его как обычный SQL скрипт, см. GDAL: PostgreSQL SQL Dump. Можно загрузить и напрямую в базу, см. документацию GDAL. Пример команды загрузки данных из дампа OSM для Германии (germany-latest.osm.pbf) в базу данных PostgreSQL (osmrouting):
ogr2ogr \ -f PGDUMP \ /vsistdout/ "germany-latest.osm.pbf" \ -nln "osm_lines" \ -nlt LINESTRING \ -progress \ --config PG_USE_COPY YES \ --config GEOMETRY_NAME the_geom \ --config OSM_COMPRESS_NODES YES \ --config OSM_CONFIG_FILE "osmconf.ini" \ -sql "select * from lines where highway is not null" \ -lco FID=id \ | psql osmroutingДампы OpenStreetMap по странам предоставляет сервис OpenStreetMap Data Extracts.
Как превратить карту дорог OpenStreetMap в дорожную сеть для роутинга
Простейший путь заключается в поиске и нумерации всех пересечений улиц и разбиении всех дорог на участки между найденными точками пересечения. Точки пересечения будут узлами дорожного графа (сети), а участки — ребрами этого графа. Узлы необходимы в процессе построения дорожной сети, а для роутинга они не нужны, хотя их удобно использовать для поиска ближайших узлов графа для заданных домов (адресов). В чем минусы такого простого подхода, хорошо описанного в документации? В первую очередь тем, что мы никак не можем ограничить пересечения дорог — и полученные маршруты будут в шахматном порядке обходить дома по обе стороны каждой дороги, что выглядит странно, в случае широких улиц такой маршрут очень далек от оптимального и, вдобавок, вовсе не все дороги можно пересечь в произвольном месте. Кроме того, по умолчанию односторонние улицы или полностью исключаются из дорожной сети, или доступны в обоих направлениях. Зато такой вариант очень прост в реализациии для него существуют и специальные утилиты и функции PgRouting.
В предложенной в репозитории дорожной сети каждое ребро разделено на два односторонних (два направления движения транспорта или два тротуара для пешеходов) и добавлены соединяющие кратчайшие пути между дорогами и домами так, чтобы добавленные сегменты соответствовали принятому направлению движения (напомню, в разных странах бывает как левостороннее, так и правостороннее движение) и необходимые узлы сети. Таким образом, сменить направление движения можно только на перекрестках и мы избегаем лишних пересечений дорог и обеспечиваем непрерывную нумерацию домов по каждую сторону каждого участка дорог. При необходимости, протяженные участки можно разбить на более короткие для возможности смены направления движения. Заметим, что такой вариант дорожной сети оптимизирован для автомобильных маршрутов.
На рисунке выше показана визуализация виртуальной дорожной сети из репозитория. На самом деле, геометрически синие и зеленые сегменты накладываются друг на друга, а здесь сделано смещение между ними только для наглядности. Здесь нумерация точек маршрута на каждой стороне последовательная, при этом направление движения на одной из сторон (синей) игнорируется, поскольку у нас пока нет поддержки однонаправленных дорог.
Для пешеходных маршрутов лучше для каждого добавленного узла связи с домами также добавить узел к парному ребру (обратного направления) и определить короткие сегменты между этими узлами, так как во многих случаях пешеходу удобнее пересекать небольшие улицы, нежели двигаться по одной стороне от перекрестка до перекрестка. Для автотранспортных маршрутов такой вариант тоже подходит, только нужно увеличить расстояние между виртуальными узлами. Скажем, 10 м для пешеходного маршрута и 100 м для автомобильного разумная оценка для каждой смены направления вне перекрестка.
Возможно, вас интересует вопрос, почему мы тратим время на создание сложной дорожной сети вместо использования более «продвинутых» методов построения оптимального маршрута? Все очень просто — по хорошей дорожной сети даже простой алгоритм быстро (секунды) построит отличные маршруты, в то время как по посредственной дорожной сети даже лучшие из существующих алгоритмов за разумное время (минуты, часы или дни, в зависимости от задачи) построят плохие маршруты или вообще не смогут завершить вычисления. Это следствие невероятной вычислительной сложности задачи. К примеру, если мы желаем посетить 10 или 100 адресов по обе стороны одной улицы и при этом у нас определены два направления движения и только два перехода между ними, скажем, в начале и в конце улицы — задача имеет единственное решение и любой алгоритм его найдет почти мгновенно! В случае же, когда у нас нет заданных направлений движения и разрешено пересечение улицы около каждого заданного адреса — задача становится не решаемой вычислительно уже для нескольких десятков адресов и разные алгоритмы и для разного числа адресов вернут разные и весьма не оптимальные маршруты. Таким образом, критически важно именно построить дорожную сеть с такими ограничениями, которые запрещают большинство (неоптимальных) маршрутов, так что пространство перебора становится несравнимо меньше и достаточно оптимальный результат гарантирован любым из методов. Именно ограничения на направление движения и допустимые повороты являются самыми эффективными.
Таблицы базы данных PostgreSQL
Мы будем работать с базой "osmrouting", содержащей несколько таблиц, содержимое которых доступно в виде PostgreSQL SQL дампов в репозитории, см. также скрипт инициализации базы данных и загрузки дампов load.sh (также загружает необходимые расширения PgRouting и PostGIS).
Первая таблица является единственной необходимой и содержит данные маршрутной сети и, по желанию, информацию для визуализации (сам алгоритм роутинга работает с идентификаторами ребер графа start_id и end_id и некоторой стоимостью каждого сегмента, задаваемой, например, его длиной length):
-- таблица с ребрами маршрутного графа (сегментами дорожной сети) -- id - идентификатор для отладки -- the_geom - геометрия дорожного сегмента для визуализации -- oneway - флаг односторонней дороги -- highway - флаг скоростного шоссе (можно запретить на нем повороты и пересечения) -- pedestrian - флаг пешеходной улицы (можно запретить движение транспорта) -- start_id - идетификатор стартового узла сегмента для роутинга -- end_id - идетификатор конечного узла сегмента для роутинга -- length - длина сегмента (может переопределяться в зависимости от типа дороги и проч.) osmrouting=# \d osm_network Table "public.osm_network" Column | Type | Collation | Nullable | Default ------------+---------------------------+-----------+----------+--------- id | integer | | | the_geom | geometry(LineString,4326) | | | type | text | | | oneway | boolean | | | highway | boolean | | | pedestrian | boolean | | | start_id | bigint | | | end_id | bigint | | | length | double precision | | | Вторая таблица не является необходимой и используется только для поиска ближайшего узла дорожной сети для заданных адресов:
-- таблица с узлами маршрутного графа -- id - идентификатор для отладки -- the_geom - геометрия дорожного узла для визуализации osmrouting=# \d osm_nodes Table "public.osm_nodes" Column | Type | Collation | Nullable | Default ----------+----------------------+-----------+----------+--------- id | bigint | | | the_geom | geometry(Point,4326) | | | Третья таблица также не является необходимой и используется только для хранения адресов и координат домов, которые мы используем в тестовых скриптах:
osmrouting=# \d osm_buildings Table "public.osm_buildings" Column | Type | Collation | Nullable | Default ----------+----------------------+-----------+----------+--------- id | character varying | | | the_geom | geometry(Point,4326) | | | ...Также тестовые скрипты создают дополнительные таблицы.
Поиск оптимального маршрута
Скрипт репозитория route.sql содержит необходимые команды для выбора случайных 330 адресов домов и построения маршрута по ним с помощью функции PgRouting pgr_TSP(). На самом деле, указанная функция работает не с координатами, а с матрицей расстояний (есть функции и для работы с координатами, см. документацию PgRouting). Матрица расстояний может быть создана функцией pgr_dijkstraCostMatrix(). Заметим, что в скрипте для генерации этой матрицы указан флаг directed=false, так как по умолчанию pgr_TSP() не работает с односторонними дорогами (точнее, не работает с несимметричной матрицей, которая получается при наличии односторонних дорог). С помощью моих функций pgr_dijkstraSymmetrizeCostMatrix() и pgr_dijkstraValidateCostMatrix() это ограничение можно обойти, как мы увидим далее. Что интересно, маршрут возвращается в виде списка идентификаторов узлов дорожного графа (в нашем случае — все узлы результата соответствуют добавленным нами виртуальным узлам для домов) и для получения маршрута в виде линии нужно полученный список идентификаторов передать в функцию pgr_dijkstraVia() для нахождения всех посещенных ребер дорожной сети в нужном порядке.
Параметр randomize=false обеспечивает выполнение нескольких запусков алгоритма роутинга и возвращение лучшего результата, для целей отладки и ускорения вычислений можно указать randomize=true, но возвращаемый результат в таком случае непредсказуем. В результате выполнения указанного SQL скрипта создается таблица "route" с сегментами маршрута для каждого заданного адреса, которую можно визуализировать с помощью программы QGIS. Файл проекта QGIS также представлен в репозитории, см. route.qgs Полученная карта с маршрутом представлена на картинке до хабраката.
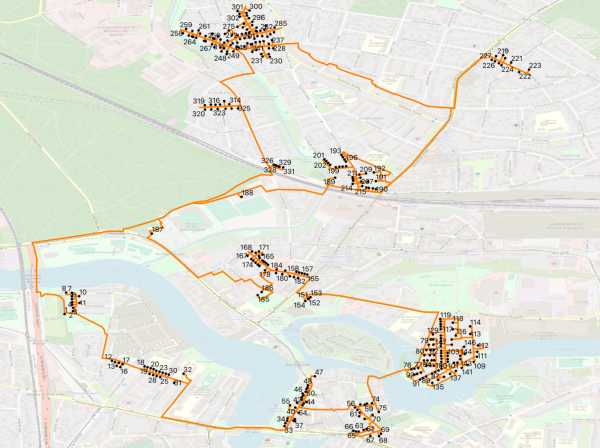
Смотрите на следующем рисунке участок дорожной сети с узлами и построенного маршрута с порядковыми номерами посещенных домов:
Кроме уже означенной проблемы с направлениями движения, местами можно заметить странный порядок нумерации — например, смотрите номера 245,246,247 и другие. Вы можете захотеть «покрутить» доступные параметры для алгоритма отжига — но, даже если это удастся сделать, найденные подходящие параметры для конкретного маршрута не помогут с любым другим маршрутом. Вместо попыток подбора параметров и увеличения времени вычисления следует заняться улучшением дорожной сети (и матрицы расстояний), например, за счет жесткого указания направлений движения.
Заключение
Сегодня мы обсудили самые основы — как получить исходные данные, подготовить маршрутную сеть и выполнить поиск оптимального маршрута средствами PgRouting. Для того, чтобы улучшить полученный маршрут (как минимум, двигаться по дорогам в правильном направлении), нам понадобится добавить некоторые свои функции, чем мы и займемся в следующей части статьи. Далее поговорим о выборе параметров маршрутизации и других улучшениях.
А вы хорошо знаете статическую маршрутизацию? / Хабр
Статический маршрут — первое, с чем сталкивается любой человек при изучении понятия маршрутизации IP пакетов. Считается, что это — наиболее простая тема из всех, в ней всё просто и очевидно. Я же постараюсь показать, что даже настолько примитивная технология может содержать в себе множество нюансов.Оговорка. При написании топика я исхожу из того, что читатель знаком с концепцией маршрутизации, умеет делать статические маршруты и не считает слово «ARP» ругательным. Впрочем, даже бывалые связисты наверняка найдут тут что-то новое.
Все примеры были проверены на IOS линейки 15.2M. Поведение других ОС может различаться.
И никакого динамического роутинга тут не будет.
Мы работаем со следующей топологией: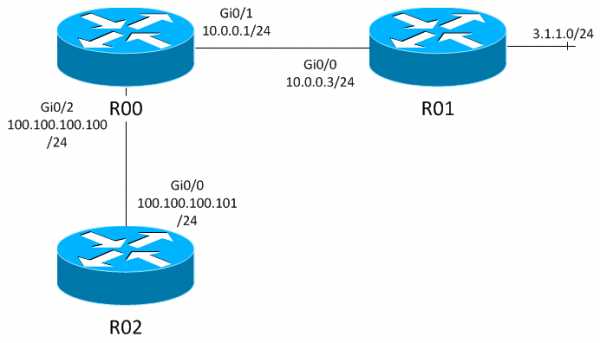
Как появляется статический маршрут?
Для начала, выполним команду, которую знает каждый, и посмотрим дебагами, что произойдет:
R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3IP-ST(default): updating same distance on 3.1.1.0/24 IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 8, no change, not active state IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 2 3 7 RT: updating static 3.1.1.0/24 (0x0): via 10.0.0.3 RT: add 3.1.1.0/24 via 10.0.0.3, static metric [1/0], add succeed, active state IP ARP: creating incomplete entry for IP address: 10.0.0.3 interface GigabitEthernet0/1 IP ARP: sent req src 10.0.0.1 30e4.db16.7791, dst 10.0.0.3 0000.0000.0000 GigabitEthernet0/1 IP ARP: rcvd rep src 10.0.0.3 0019.aad6.ae10, dst 10.0.0.1 GigabitEthernet0/1IOS создал маршрут, и сразу послал arp запрос в поисках next hop, который у нас – 10.0.0.3. И сразу вопрос: откуда роутер узнал, что запрос надо слать в интерфейс Gi0/1? Наверняка кто-то скажет «из списка локальных интерфейсов», и жестоко ошибется. Маршрутизация так не работает. На самом деле, IOS сделал рекурсивный запрос к таблице маршрутизации, чтобы узнать, как добраться до next hop:
R00#show ip route 10.0.0.3 Routing entry for 10.0.0.0/24 Known via "connected", distance 0, metric 0 (connected, via interface) Routing Descriptor Blocks: * directly connected, via GigabitEthernet0/1 Route metric is 0, traffic share count is 1И вот он, наш Gi0/1. IOS узнает, что с рекурсивными запросами к RIB надо заканчивать, как только находит маршрут с флагом «directly connected». Но что если ему в ответ на изначальный запрос к 10.0.0.3 вернется вовсе не connected маршрут, а промежуточный, ссылающийся на другой next hop? Вернемся к этому чуть позже, а пока вспомним, что такое CEF.
Примерно во всей документации, ориентированной на начинающих, говорится, что каждый пакет перемещается в соответствии с таблицей маршрутизации. На самом деле на всех более-менее современных платформах это уже не так, ведь таблица маршрутизации (далее – RIB) вовсе не оптимизирована для быстрой передачи данных. Оценить масштаб бедствия позволяет эта таблица (хотя у process switching’а множество недостатков помимо неоптимальных запросов – например, постоянное переключение шедулера CPU между контекстами, что весьма затратно). CEF является серьезной оптимизацией. В современной реализации он строит две таблицы – FIB (Forwarding Information Base, таблица передачи пакетов, в основе нее – связный граф со страшным названием 256-way mtrie) и adjacency table (таблица соседств). Первая из них строится на основе таблицы маршрутизации и за один проход позволяет получить всю нужную информацию. Строится она заранее, еще до того, как появится первый соответствующий ей пакет.
Вернемся к нашему статическому маршруту. Вот запись в таблице маршрутизации:
R00#show ip route 3.1.1.0 Routing entry for 3.1.1.0/24 Known via "static", distance 1, metric 0 Routing Descriptor Blocks: * 10.0.0.3 Route metric is 0, traffic share count is 1Куда слать пакет? Где искать 10.0.0.3? Непонятно. Надо еще раз запросить таблицу маршрутизации, на этот раз по поводу 10.0.0.3, и, если надо, выполнить еще несколько итераций, пока не выясним connected интерфейс. И вот примерно таким образом мы фактически в несколько раз снижаем производительность маршрутизатора.
А вот что говорит CEF:
R00#show ip cef 3.1.1.0 detail 3.1.1.0/24, epoch 0 recursive via 10.0.0.3 attached to GigabitEthernet0/1Просто и лаконично. Есть интерфейс, есть next hop, к которому надо слать пакет. Что там говорилось про adjacency table?
R00#show adjacency 10.0.0.3 detail Protocol Interface Address IP GigabitEthernet0/1 10.0.0.3(10) 0 packets, 0 bytes epoch 0 sourced in sev-epoch 2 Encap length 14 0019AAD6AE1030E4DB1677910800 ARPОбратим внимание на какую-то длинную последовательность в предпоследней строке. Что-то это напоминает… Смотрим mac 10.0.0.3:
R00#show arp | in 10.0.0.3 Internet 10.0.0.3 1 0019.aad6.ae10 ARPA GigabitEthernet0/1Смотрим свой mac адрес на gi0/1:
R00#show int gi0/1 GigabitEthernet0/1 is up, line protocol is up Hardware is CN Gigabit Ethernet, address is 30e4.db16.7791 (bia 30e4.db16.7791)Ага. Та страшная строка – всего лишь два мака, которые надо подставить в заголовок Ethernet на этапе инкапсуляции, и ethertype 0x0800, т.е. банальный IPv4. И в двух таблицах CEF есть абсолютно вся информация, какая нужна для успешной отправки пакета дальше по цепочке.
Если у кого-то возникнет вопрос, зачем железке держать сразу две таблицы вместо одной, то дам очевидный ответ: обычно у маршрутизатора мало интерфейсов (а заодно и соседей) и много маршрутов. Какой смысл тысячи раз дублировать одни и те же маки в FIB? Памяти много не бывает, особенно на аппаратных платформах, будь то новомодные ASR’ы или даже L3 свитчи линейки Catalyst. Все они задействуют CEF при передаче пакетов.
И кстати, вернемся на минутку к изначальному дебагу. Отключим CEF командой no ip cef (никогда так не делайте) и сравним результат:
IP-ST(default): updating same distance on 3.1.1.0/24 IP-ST(default): 3.1.1.0/24 [1], 10.0.0.100 Path = 8, no change, not active state IP-ST(default): 3.1.1.0/24 [1], 10.0.0.100 Path = 2 3 7 RT: updating static 3.1.1.0/24 (0x0): via 10.0.0.100 RT: add 3.1.1.0/24 via 10.0.0.100, static metric [1/0], add succeed, active stateМаршрут добавлен. Arp запроса не было. И правильно – зачем RIB сдался mac адрес? Если пустить пинг до, к примеру, 3.1.1.1, то скорее всего будет так:
R00#ping 3.1.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 3.1.1.1, timeout is 2 seconds: .!!!! Success rate is 80 percent (4/5), round-trip min/avg/max = 1/1/4 msПервый пакет отбрасывается, и роутер посылает arp запрос с целью узнать mac адрес 10.0.0.3, если он ранее не был известен. CEF же всегда заранее узнает mac адрес next hop'а.
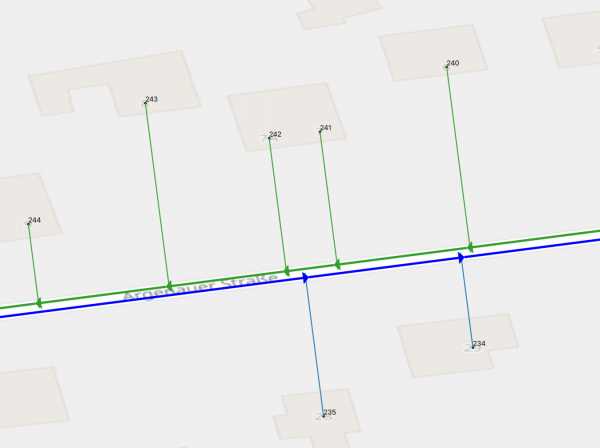
С этим разобрались. Теперь вернемся к вопросу, что будет, если next hop статического маршрута вовсе не на directly connected интерфейсе. Поступим просто:
R00(config)#ip route 10.0.0.3 255.255.255.255 100.100.100.101, где Gi0/2 имеет адрес 100.100.100.100/24.
R00#show ip cef 3.1.1.0 detail 3.1.1.0/24, epoch 0 recursive via 10.0.0.3 recursive via 100.100.100.101 recursive via 100.100.100.0/24 attached to GigabitEthernet0/2Как все плохо-то… А что если у нас есть маршрут на целую суперсеть?
R00(config)#no ip route 10.0.0.3 255.255.255.255 100.100.100.101 R00(config)#ip route 10.0.0.0 255.0.0.0 100.100.100.101 R00#show ip cef 3.1.1.0 detail 3.1.1.0/24, epoch 0 recursive via 10.0.0.3 attached to GigabitEthernet0/1Сейчас наша таблица маршрутизации выглядит так:
R00#show ip route 10.0.0.0/8 is variably subnetted, 2 subnets, 3 masks S 10.0.0.0/8 [1/0] via 100.100.100.101 C 10.0.0.0/24 is directly connected, GigabitEthernet0/1 L 10.0.0.1/32 is directly connected, GigabitEthernet0/1 100.0.0.0/8 is variably subnetted, 2 subnets, 2 masks C 100.100.100.0/24 is directly connected, GigabitEthernet0/2 L 100.100.100.100/32 is directly connected, GigabitEthernet0/2Вроде хорошо. Новый маршрут на 100.100.100.101 не применяется для 10.0.0.3, так как его маска /8 намного короче, чем /24 у connected интерфейса. Но вдруг Gi0/1, содержавший next hop для 3.1.1.0/24, по какой-то непонятной причине ушел в down, и его connected маршрут пропал из RIB.
%LINK-5-CHANGED: Interface GigabitEthernet0/1, changed state to administratively down %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet0/1, changed state to down RT: interface GigabitEthernet0/1 removed from routing table RT: del 10.0.0.0 via 0.0.0.0, connected metric [0/0] RT: delete subnet route to 10.0.0.0/24 RT: del 10.0.0.1 via 0.0.0.0, connected metric [0/0] RT: delete subnet route to 10.0.0.1/32 IP-ST(default): updating GigabitEthernet0/1Вот что стало:
R00#show ip cef 3.1.1.0 detail 3.1.1.0/24, epoch 0 recursive via 10.0.0.3 recursive via 10.0.0.0/8 recursive via 100.100.100.101 recursive via 100.100.100.0/24 attached to GigabitEthernet0/2Ой. Теперь пакеты на сеть 3.1.1.0/24 идут куда-то не туда. Я не могу представить себе сценарий, когда ожидаемое поведение статического маршрута – переключение на другой интерфейс. Если за тем интерфейсом находится резервный путь, то все-таки надо создавать еще один статический маршрут…
Что делать? Указывать сразу в маршруте интерфейс. Пересоздадим маршрут:
R00(config)#no ip route 3.1.1.0 255.255.255.0 10.0.0.3 R00(config)#ip route 3.1.1.0 255.255.255.0 Gi0/1 10.0.0.3Поднимаем Gi0/1. Смотрим, куда теперь ведет маршрут на 3.1.1.0/24:
R00#show ip route 3.1.1.0 Routing entry for 3.1.1.0/24 Known via "static", distance 1, metric 0 Routing Descriptor Blocks: * 10.0.0.3, via GigabitEthernet0/1 Route metric is 0, traffic share count is 1Тут уже указан интерфейс. Поэтому не будет рекурсивных запросов к таблице маршрутизации. Проверяем FIB:
R00#show ip cef 3.1.1.0 3.1.1.0/24 nexthop 10.0.0.3 GigabitEthernet0/1Да, никакого «recursive». А если снова погасить gi0/1? Маршрут исчез.
R00#show ip route 3.1.1.0 % Network not in table R00#show ip cef 3.1.1.0 0.0.0.0/0 no routeИ это притом, что маршрут до 10.0.0.3 все еще был:
R00#show ip cef 10.0.0.3 10.0.0.0/8 nexthop 100.100.100.101 GigabitEthernet0/2А что будет, если путь к next hop даст маршрут по умолчанию, а маршрут на 3.1.1.0/24 не ссылается на интерфейс?
R00(config)#no ip route 10.0.0.0 255.0.0.0 100.100.100.101 R00(config)#ip route 0.0.0.0 0.0.0.0 100.100.100.101 R00(config)#no ip route 3.1.1.0 255.255.255.0 Gi0/1 10.0.0.3 R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3 R00#show ip route 3.1.1.0 % Network not in table R00#show ip cef 3.1.1.0 detail 0.0.0.0/0, epoch 0, flags default route recursive via 100.100.100.101 recursive via 100.100.100.0/24 attached to GigabitEthernet0/2Обратите внимание, что первой строкой после «show ip cef» идет «0.0.0.0/0», а не «3.1.1.0/24». Несмотря на то, что next hop формально есть, по факту все итерации опроса таблицы маршрутизации (кроме первой) игнорируют маршрут по умолчанию, что логично, иначе любой запрос к таблице маршрутизации почти всегда бы резолвился (под «резолвиться» понимается нахождение интерфейса, в который нужно отправить пакет). Поэтому наш статический маршрут отсутствует, но пакеты все равно улетают к Gi0/2. Вроде бы все то же самое, что и без явного указания интерфейса? Не совсем. Допустим, протоколу маршрутизации сказали «redistribute static». Если статический маршрут пропал, то анонс тоже отзывается. А если нет, то маршрутизатор продолжит говорить всем «туда идти через меня», и это почти наверняка обернется L3 кольцом для префикса 3.1.1.0/24, который мог бы быть доступен откуда-нибудь еще. Но стоп, мы договаривались не трогать динамический роутинг…
А что если в статическом маршруте указать интерфейс, но не указывать IP адрес следующего хопа? Ответ: в случае Ethernet, если на next hop не отключен proxy arp, связность не нарушится, но роутеру может ОЧЕНЬ поплохеть. Подробнее. Если сказать «ip route 3.1.1.0 255.255.255.0 gi0/1», то ничего особо страшного не случится, даже пару сотен записей в arp таблице любой роутер переварит (и существуют сценарии-workaround’ы, в которых оптимальным решением является именно такой костыль), но вот «ip route 0.0.0.0 0.0.0.0 gi0/1» на пограничном маршрутизаторе наверняка убьет его. Потому запомните общее правило: если создается статический маршрут с next hop’ом на Ethernet интерфейсе, то его IP адрес должен указываться всегда. Исключения – только когда вы очень хорошо представляете себе, что делаете, зачем делаете и почему нельзя сделать иначе.
И напоследок, сделаем одну очень нехорошую штуку.
R00(config)# ip route 3.1.1.0 255.255.255.0 10.0.0.3 R00(config)#ip route 10.0.0.3 255.255.255.255 3.1.1.1Первый маршрут в порядке, сто раз протестирован. А вот второй странный – он ведет через первый. А первый теперь ссылается на второй, и у нас бесконечная рекурсия. Вот что произошло:
IP-ST(default): updating same distance on 3.1.1.0/24 IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 8, no change, not active state IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 2 3 7 RT: updating static 3.1.1.0/24 (0x0): via 10.0.0.3 RT: add 3.1.1.0/24 via 10.0.0.3, static metric [1/0], add succeed, active state IP-ST(default): updating same distance on 10.0.0.3/32 IP-ST(default): 10.0.0.3/32 [1], 3.1.1.1 Path = 8, no change, not active state IP-ST(default): 10.0.0.3/32 [1], 3.1.1.1 Path = 2 3 7 RT: updating static 10.0.0.3/32 (0x0): via 3.1.1.1 RT: add 10.0.0.3/32 via 3.1.1.1, static metric [1/0], add succeed, active stateДобавилось успешно. Но затем в дебагах высветилось:
RT: recursion error routing 3.1.1.1 - probable routing loop RT: recursion error routing 10.0.0.3 - probable routing loopИ появилась запись в лог с severity 3:
%IPRT-3-RIB_LOOP: Resolution loop formed by routes in RIBR00#show ip cef 10.0.0.3 detail 10.0.0.3/32, epoch 0 Adj source: IP adj out of GigabitEthernet0/1, addr 10.0.0.3 359503C0 Dependent covered prefix type adjfib cover 10.0.0.0/24 1 RR source [no flags] recursive via 3.1.1.1, unresolved recursive-looped R00#show ip cef 3.1.1.0 detail 3.1.1.0/24, epoch 0, flags cover dependents Covered dependent prefixes: 1 notify cover updated: 1 recursive via 10.0.0.3, unresolved recursive-loopedОднако, RIB никакого криминала не видит:
Routing entry for 3.1.1.0/24 Known via "static", distance 1, metric 0 Routing Descriptor Blocks: * 10.0.0.3 Route metric is 0, traffic share count is 1 R00#show ip route 10.0.0.3 Routing entry for 10.0.0.3/32 Known via "static", distance 1, metric 0 Routing Descriptor Blocks: * 3.1.1.1 Route metric is 0, traffic share count is 1Вывод – никогда так не делайте.
Почему статический маршрут может не попасть в таблицу маршрутизации?
Любой сетевик должен сходу дать одно из объяснений, касающееся любого источника маршрутов в IOS: существует другой маршрут на тот же самый префикс, но с меньшим AD (все помнят Administrative Distance?). Маршрут, источник которого – “connected”, всегда имеет AD=0, и ни один другой источник маршрутов не может привнести ничего ниже, чем «1», даже статический маршрут с явным указанием интерфейса. Пример connected:
R00# show ip route C 10.0.0.0/24 is directly connected, GigabitEthernet0/1Т.е. пока интерфейс Gi0/1 находится в состоянии up и имеет адрес из подсети 10.0.0.0/24, ни один статический маршрут на этот префикс в таблице маршрутизации не появится.
Еще есть вариант «разные источники маршрутов добавляют маршруты на один и тот же префикс с одинаковым AD». Поведение IOS в данном случае не документировано, общая рекомендация – «никогда так делайте».
Но посмотрим другие, менее очевидные примеры. Например, статические маршруты можно создать со словом «permanent», которое переводится как «постоянный», и тогда они будут всегда висеть в таблице маршрутизации. Правильно? Нет.
Добавляем его и смотрим:
R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3 permanent R00#show ip cef 3.1.1.0 3.1.1.0/24 nexthop 10.0.0.3 GigabitEthernet0/1Кладем Gi0/1, и видим:
R00#show ip cef 3.1.1.0 3.1.1.0/24 unresolved via 10.0.0.3В RIB он есть, и другие протоколы маршрутизации могут его использовать:
R00#show ip route 3.1.1.0 Routing entry for 3.1.1.0/24 Known via "static", distance 1, metric 0 Routing Descriptor Blocks: * 10.0.0.3, permanent Route metric is 0, traffic share count is 1А теперь, не поднимая Gi0/1:
R00(config)#no ip route 3.1.1.0 255.255.255.0 10.0.0.3 permanent R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3 permanentПросто пересоздали его, ничего не меняя. И вот что произошло:
IP-ST(default): updating same distance on 3.1.1.0/24 IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 8, no change, not active state IP-ST(default): cannot delete, PERMANENT R00#show ip route 3.1.1.0 % Network not in table R00#show ip cef 3.1.1.0 0.0.0.0/0 no routeПостоянный, говорите? Нет. Есть один маленький нюанс: чтобы перманентный маршрут навеки вписался в таблицу маршрутизации, нужно, чтобы он хотя бы на долю секунды резолвился. Хотя какое еще «навеки»? Когда он остался висеть в воздухе без резолвящегося интерфейса, достаточно сказать «clear ip route *» или тем более «reload», чтобы он исчез из RIB.
Но продолжим. Сделаем вот так:
R00(config)#ip route 3.1.1.0 255.255.255.0 Gi0/1 10.0.0.3 R00(config)#ip route 3.1.1.10 255.255.255.255 3.1.1.1Вроде нормальные маршруты. Что произойдет? Со вторым – ровным счетом ничего.
IP-ST(default): 3.1.1.10/32 [1], 3.1.1.1 Path = 8, no change, not active state IP-ST(default): 3.1.1.10/32 [1], 3.1.1.1 Path = 2 3 6 8, no change, not active stateСуть вот в чем. Допустим, есть маршрут на X.X.X.X через Y.Y.Y.Y. Мы добавляем маршрут на X1.X1.X1.X1 (этот префикс полностью покрывается X.X.X.X) через X2.X2.X2.X2 (а он тоже покрывается X.X.X.X). IOS делает закономерный вывод: второй маршрут не несет в себе никакой новой информации и совершенно бесполезен, поэтому его можно не устанавливать в RIB.
А теперь финт ушами.
R00(config)#no ip route 3.1.1.10 255.255.255.255 3.1.1.1 R00(config)#ip route 3.1.1.10 255.255.255.255 Gi0/1 3.1.1.1 IP-ST(default): updating same distance on 3.1.1.10/32 IP-ST(default): 3.1.1.10/32 [1], GigabitEthernet0/1 Path = 1 RT: updating static 3.1.1.10/32 (0x0): via 3.1.1.1 Gi0/1 RT: network 3.0.0.0 is now variably masked RT: add 3.1.1.10/32 via 3.1.1.1, static metric [1/0], add succeed, active state IP ARP: creating incomplete entry for IP address: 3.1.1.1 interface GigabitEthernet0/1 IP ARP: sent req src 10.0.0.1 30e4.db16.7791, dst 3.1.1.1 0000.0000.0000 GigabitEthernet0/1 R00#show ip cef 3.1.1.10 3.1.1.10/32 nexthop 3.1.1.1 GigabitEthernet0/1 И вот это подводит нас к еще одному важному моменту. Указание интерфейса в статическом маршруте позволяет обойти многие проверки, так как статическому маршруту больше не требуется выполнять рекурсивные запросы к RIB в поисках пути до next hop, и при своем добавлении он не заденет триггеры на других маршрутах. Но это не отменяет главного требования: next hop обязан резолвиться в конкретный интерфейс, а тот интерфейс обязан быть в up. Тот факт, что рекурсивных запросов к RIB больше не будет, означает, что указанный IP адрес next hop’а находится прямо за интерфейсом, и наверняка отзовется на arp запрос (с точки зрения роутера). Если у соседнего по Gi0/1 роутера включен proxy arp, то он в ответ на arp запрос наверняка вернет свой mac адрес, и всё будет хорошо. Разве что лишняя запись в arp таблице…
Но все равно так делать не стоит.
Необходимо упомянуть и о еще одном важном моменте. Статический маршрут должен по идее исчезнуть из таблицы маршрутизации, как только он перестанет резолвиться. Но на практике есть множество ситуаций, когда next hop пропадает, но при этом статический маршрут на какое-то время остается. К примеру, когда next hop резолвится через маршрут, полученный от протокола динамической маршрутизации. Все дело в том, что процесс, отслеживающий наличие next hop в RIB, не всегда может получить уведомление об исчезновении маршрута, и он вынужден периодически (раз в 60 секунд по умолчанию) перепроверять, все ли хорошо. Это вызовет заметную задержку сходимости сети.
Поменять интервал проверки, к примеру, на 10 секунд можно с помощью команды:
ip route static adjust-time 10Policy-based Routing (PBR), как основное назначение (Часть 1) / Хабр
Что такое Policy-based Routing (PBR)Policy-based routing (PBR) перевод данного словосочетания несет смысл такого характера, как маршрутизация на основе определенных политик (правил, условий), которые являются относительно гибкими и устанавливаются Администратором. Другими словами это технология предоставляет условия гибкой маршрутизации (если смотреть на технологию с первоочередной ее задачи), по источнику или назначению пакета.
Где применяется
Применение данной технологии очень часто используется для организации избыточности в небольших офисах, при нескольких каналах связи с «вешним миром», «гуглится» примерно таким запросом (PBR 2 ISP). Ну, или другими аналогичными. Если вы «погуглите» то для избыточности нужно будет помимо PBR еще такие штуки как Tracking, SLA, на них я сильно внимание не буду заострять, как сейчас так и в дальнейшей части статьи.
Кратко про SLA и tracking — это две технологии, точнее связка двух технологий (в нашем случае), которые генерируют различного рода icmp трафик (при заданных условиях), это я про SLA, и выполняют мониторинг данного генератора, а это про tracking.
Так же PBR находит применение в настройках динамических протоколах маршрутизации (к примеру BGP; OSPF;EIGRP)для фильтрации и redistributions (перенаправления) роутов ну и мелочей типа изменение метрики маршрутов и т.п., и в статической маршрутизации (раскроется ниже), В построение механизмов улучшение качества сервисов (QoS). Возможно, что-то забыл, уж не обессудьте. В дальнейшем, в статье, я не буду раскрывать тему применения PBR в BGP, QoS, OSPF.
Основы конструкции
Собственно карта выглядит таким образом:
Route-map namemap permit 5
match int fa0/0
set ip default next-hop 10.10.10.1
Разберем по порядку:
Первая строка (route-map namemap [permit | deny] [sequence-number]) содержит непосредственно команду которая открывает нашу карту (route -map), далее идет имя карты (namemap), для дальнейшего применение к политике этой карты затем идет permit (так как мы хотим, что бы трафик при выполнении условии описанных ниже выполнял действие). Т.е. идет перенаправление пакетов на шлюз 10.10.10.1. Вместо параметра permit может выступать параметр deny, но он не так часто применяется. В большей степени он применяется только при redistributions (перенаправления), в динамических протоколах маршрутизации, а если быть точнее, наоборот, при deny не производить redistributions (перенаправления). Для нижеуказанного условия карты, последним параметром идет sequence-number он у нас 5 т.е. порядковый номер карты, он удобен для логического представления карт с одним и тем же именем. Так же для удобства администрирования карты (удаления в частности).
Вторая строка (match interface fa0/0), содержит условие, для какого трафика применять нашу карту. В нашем случае, у нас будет применяться весь трафик проходящий через интерфейс маршрутизатора fastethernet0/0. Тут можно по различным критериям делать выборку, как правило, все рисуют карту по access-lists (листам доступа) т.е. рисуют access-list с параметрами для каких сетей применять карту. Примеры access-lists с легким комментарием представлены ниже.access-list 101 permit ip 192.168.0.0 0.0.0.255 any
### этот access-list примененный к route-maps будет выбирать трафик сети 192.168.0.0/24
до любого назначения.
А при применении такого access-lists
access-list 101 deny ip 192.168.0.0 0.0.0.255 host 192.168.2.44
access-list 101 deny ip 192.168.0.0 0.0.0.255 192.168.1.0 0.0.0.31
access-list 101 permit ip 192.168.0.0 0.0.0.255 any
### в первой строчке не будет перенаправлять трафик до хоста 192.168.2.44
### по второй строке так же не будет перенаправлять на сеть 192.168.1.0/27
### ну и по третьей строке будет применять для всего остального трафика, сети 192.168.0.0/24.
Так же добавить хочется что параметр match повторяющийся, т.е. выборку можно делать по нескольким критериям. К примеру метим по access-lists, и параллельно по размеру пакета match length min max, где min max это диапазон размера пакета от и до). И еще маленькое дополнение к этому параметру он не является обязательным. Другими словами если не делать выборку по критериям, то карта будет применяться ко всем пакетам, проходящим через интерфейс на который мы применим нашу карту маршрутизации.
Переходя к следующему параметру, скажу, что если вы выполните подкоманду set ? то помощь, вам покажет много значений, в основном эти значения направлены на опять же динамические протоколы маршрутизации. На данный момент я решил их не касаться (я планирую написать статьи про динамическую маршрутизацию, там и вернемся к ним). А перейдем сразу к set ip
Мы взяли в пример set ip default next-hop 10.10.10.1
Тут мы опять же рассмотрим ключевое слово default, оно означает, что если не будет роутов в глобальной таблице маршрутизации информации о сети назначения пакета, то будет отрабатывать наша карта и пакет будет отправлен на следующий шаг в данном случае 10.10.10.1.
Можно написать явный set ip next-hop 10.10.10.1 и тогда пакет в не зависимости от глобальной таблицы будет перенаправлен на наш next-hop, т.е. пакет попавший в критерий что он пришел на интерфейс fa0/0, отправится на 10.10.10.1 и он уже будет решать что с этим пакетом делать.
Далее рассматривая параметр set ip, можно задать следующий шагом(next-hop) как определенный ip адрес, для последующей маршрутизации, так непосредственно интерфейс. К примеру set ip next-hop interface Dialer1), это удобно когда у вас, к примеру не статический адрес на next-hop-е, а динамический и вы не можете явно прописать адрес 3-го уровня, ну или если вы забыли какой ip адрес у вас на интерфейсе и вам лень посмотреть. Как было подмечено ниже в комментариях, не стоит указывать интерфейсы, на которых прописана сеть с большим количеством хостов в сети, другими словами использовать стоит при point to point сети (с префиксов 30 ).Другие параметры set ip, используются для изменения параметров ip пакета. Установка маркирования приоритета пакета в QoS(set ip precedence 3), или сброса параметра пакета don’t fragments (set ip df 0), что позволит установить размер пакета, какой нужен маршрутизаторам для дальнейшей передачи по каналам связи.
Остается мелочь повесить route-map на интерфейс через который приходят пакеты нуждающиеся в перенаправлении пакетов в отличие от дефолтного маршрута глобальной таблицы маршрутизации. И получится такой листинг Route-map namemap permit 5
match int fa0/0
set ip default next-hop 10.10.10.1
interface FastEthernet0/0
encapsulation dot1Q 20
ip address 192.168.0.1 255.255.255.0
ip policy route-map namemap
Прошу заметить, что данная конфигурация не совсем правильная в нашем случае, хотя рабочая. Тут сами подумайте, чем она не корректна, и какие условия нужно изменить.
Послесловие:
В этой части я попытался раскрыть азы PBR и как он работает с пакетами. Если у меня это получилось не внятно, прошу указать на ошибки. Буду очень признателен. В части 2 я опишу еще несколько моментов касающихся PBR, и приведу примеры построения маршрутизации, для конкретных случаев.
UPD вот собственно и попытка продолжения часть 2
Материал для статьи брался из головы, так что литературу указать не смогу, разве что www.
P.S статья эта была в песочнице, мне кто-то дал приглашение на хабр, но так как я был в офлайне долгое время приглашение утратило силу свою. хочу сказать спасибо товарищу который дал инвайт. сейчас я по приглашению smartov, мы с ним знакомы по другому ресурсу в сети. Ему так же благодарность за приглашение.
Posted by Mario
Определение и значение маршрутизации | Что такое маршрутизация?
В сети маршрутизация - это процесс перемещения пакета данных от источника к месту назначения. Принципы маршрутизации могут применяться ко многим сетям, таким как сети с коммутацией каналов и компьютерные сети. Маршрутизация обычно выполняется специализированным устройством, известным как маршрутизатор.
Маршрутизация - это ключевая функция Интернета, при которой маршрутизатор выбирает пути для пакетов Интернет-протокола (IP) от их источника до места назначения.Процесс маршрутизации, выполняемый маршрутизатором, обычно направляет пересылку на основе таблиц маршрутизации, в которых хранятся записи маршрутов к различным сетевым адресатам. Таблицу маршрутов можно сравнить с расписанием поездов, где пассажиры поезда сверяются с расписанием, чтобы решить, на какой поезд сесть. Таблицы маршрутизации действуют таким же образом, но для сетевых путей, а не для поездов. Эти таблицы могут быть указаны администратором, изучены путем наблюдения за сетевым трафиком или созданы с помощью протоколов маршрутизации.
Как работает маршрутизация
Когда маршрутизатор получает пакет, он считывает заголовки пакета, чтобы увидеть его предполагаемое место назначения. Затем он определяет, куда направить пакет, на основе информации в своей таблице маршрутизации. По мере того как пакет перемещается к месту назначения, он может несколько раз маршрутизироваться несколькими маршрутизаторами. Маршрутизаторы выполняют этот процесс миллионы раз в секунду с миллионами пакетов.
Типы маршрутизации
Существует три основных типа маршрутизации:
- Статическая маршрутизация: Маршруты вручную добавляются в таблицу маршрутизации.При таком типе маршрутизации можно использовать более дешевый маршрутизатор, поскольку центральный процессор (ЦП) маршрутизатора не требует дополнительных затрат на маршрутизацию. Статическая маршрутизация повышает безопасность и не требует использования полосы пропускания между маршрутизаторами.
- Маршрутизация по умолчанию: маршрутизатор настроен на отправку всех пакетов одному маршрутизатору. Этот тип обычно используется с маршрутизатором-заглушкой, который представляет собой маршрутизатор, у которого есть только один маршрут для доступа ко всем другим сетям.
- Динамическая маршрутизация: корректировка маршрутов выполняется автоматически в соответствии с текущим состоянием маршрута в таблице маршрутизации.Динамическая маршрутизация использует протоколы для обнаружения сетевых пунктов назначения и маршрутов для их достижения. Его легко настроить, и он более эффективен при выборе наилучшего маршрута к удаленной сети назначения.
Ссылки по теме
.реагирующий маршрутизатор - что такое маршрутизация? Зачем нужна «маршрутизация» в одностраничных веб-приложениях?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
Коммуникационные сети / маршрутизация - Викиучебники, открытые книги для открытого мира
Из Wikibooks, открытые книги для открытого мира
Перейти к навигации Перейти к поиску| Найдите Коммуникационные сети / маршрутизация в одном из дочерних проектов Викиучебника: Викиучебник не имеет страницы с таким точным названием. Другие причины, по которым это сообщение может отображаться:
|
Что такое IP-маршрутизация?
IP-маршрутизация - это процесс отправки пакетов с хоста в одной сети на другой хост в другой удаленной сети. Этот процесс обычно выполняется маршрутизаторами. Маршрутизаторы проверяют IP-адрес назначения пакета, определяют адрес следующего перехода и пересылают пакет. Маршрутизаторы используют таблицы маршрутизации для определения адреса следующего перехода, на который должен быть перенаправлен пакет.
Рассмотрим следующий пример IP-маршрутизации:
Хост A хочет установить связь с хостом B, но хост B находится в другой сети.Хост A настроен для отправки всех пакетов, предназначенных для удаленных сетей, на маршрутизатор R1. Маршрутизатор R1 принимает пакеты, проверяет IP-адрес назначения и пересылает пакет на исходящий интерфейс, связанный с сетью назначения.
Шлюз по умолчанию
Шлюз по умолчанию - это маршрутизатор, который хосты используют для связи с другими хостами в удаленных сетях. Шлюз по умолчанию используется, когда хост не имеет записи маршрута для конкретной удаленной сети и не знает, как достичь этой сети.Хосты могут быть настроены для отправки всех пакетов, предназначенных для удаленных сетей, на шлюз по умолчанию, у которого есть маршрут для достижения этой сети.
В следующем примере более подробно объясняется концепция шлюза по умолчанию.
Хост A имеет IP-адрес маршрутизатора R1, настроенный как адрес шлюза по умолчанию. Хост A пытается связаться с хостом B, хостом в другой удаленной сети. Хост A просматривает свою таблицу маршрутизации, чтобы проверить, есть ли запись для этой сети назначения.Если запись не найдена, хост отправляет все данные маршрутизатору R1. Маршрутизатор R1 принимает пакеты и пересылает их на хост B.
Таблица маршрутизации
Каждый маршрутизатор поддерживает таблицу маршрутизации и сохраняет ее в ОЗУ. Таблица маршрутизации используется маршрутизаторами для определения пути к сети назначения. Каждая таблица маршрутизации состоит из следующих записей:
- сетевой пункт назначения и маска подсети - указывает диапазон IP-адресов.
- удаленный маршрутизатор - IP-адрес маршрутизатора, который используется для доступа к этой сети.
- исходящий интерфейс - исходящий интерфейс, пакет должен выйти, чтобы достичь сети назначения.
Существует три различных метода заполнения таблицы маршрутизации:
- подсети с прямым подключением
- с использованием статической маршрутизации
- с использованием динамической маршрутизации
Каждый из этих методов будет описан в следующих главах.
Рассмотрим следующий пример. Хост A хочет связаться с хостом B, но хост B находится в другой сети.Хост A настроен для отправки на маршрутизатор всех пакетов, предназначенных для удаленных сетей. Маршрутизатор получает пакеты, проверяет таблицу маршрутизации, чтобы увидеть, есть ли в ней запись для адреса назначения. Если это так, маршрутизатор пересылает пакет через соответствующий интерфейсный порт. Если маршрутизатор не находит запись, он отбрасывает пакет.
Мы можем использовать команду show ip route из включенного режима для отображения таблицы маршрутизации маршрутизатора.
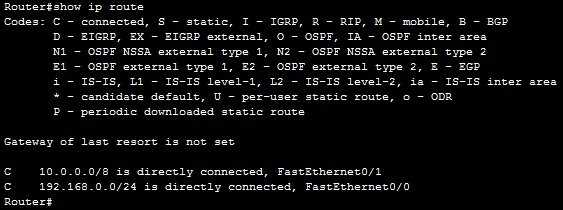
Как видно из выходных данных выше, у этого маршрутизатора есть два напрямую подключенных маршрута к подсетям 10.0.0.0 / 8 и 192.168.0.0/24. Символ C в таблице маршрутизации указывает, что маршрут представляет собой маршрут с прямым подключением. Поэтому, когда хост A отправляет пакет хосту B, маршрутизатор просматривает свою таблицу маршрутизации и находит маршрут к сети 10.0.0.0/8, в которой находится хост B. Затем маршрутизатор будет использовать этот маршрут для маршрутизации пакетов, полученных от хоста A, на хост B.
.таблиц маршрутизации в компьютерной сети
Маршрутизаторы:
Маршрутизатор - это сетевое устройство, которое пересылает пакеты данных между компьютерной сетью. Это устройство обычно подключено к двум или более разным сетям. Когда пакет данных поступает на порт маршрутизатора, маршрутизатор считывает адресную информацию в пакете, чтобы определить, на какой порт будет отправлен пакет. Например, маршрутизатор предоставляет вам доступ в Интернет, соединяя вашу локальную сеть с Интернетом.
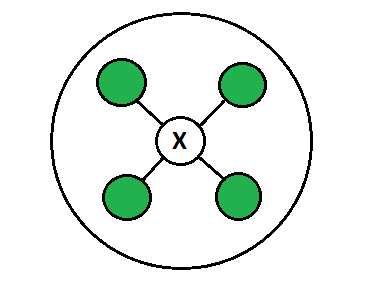
Когда пакет достигает маршрутизатора, он проверяет IP-адрес получателя полученного пакета и принимает соответствующие решения о маршрутизации. Маршрутизаторы используют таблицы маршрутизации , чтобы определить, на какой интерфейс будет отправлен пакет. В таблице маршрутизации перечислены все сети, для которых известны маршруты. Таблица маршрутизации каждого маршрутизатора уникальна и хранится в оперативной памяти устройства.
Таблица маршрутизации:
Таблица маршрутизации - это набор правил, часто просматриваемых в табличном формате, который используется для определения того, куда будут направляться пакеты данных, проходящие по сети Интернет-протокола (IP).Все IP-устройства, включая маршрутизаторы и коммутаторы, используют таблицы маршрутизации. См. Ниже таблицу маршрутизации:
Назначение Маска подсети Интерфейс 128.75.43.0 255.255.255.0 Eth0 128.75.43.0 255.255.255.128 Eth2 192.12.17.5 255.255.255.255 Eth4 по умолчанию Eth3
Запись, соответствующая конфигурации шлюза по умолчанию , является сетевым адресатом 0.0.0.0 с сетевой маской (сетевой маской) 0.0.0.0. Маска подсети маршрута по умолчанию всегда 255.255.255.255.
Записи в таблице IP-маршрутизации:
Таблица маршрутизации содержит информацию, необходимую для пересылки пакета по наилучшему пути к месту назначения. Каждый пакет содержит информацию о его происхождении и назначении. Таблица маршрутизации предоставляет устройству инструкции по отправке пакета на следующий переход на его маршруте по сети.
Каждая запись в таблице маршрутизации состоит из следующих записей:
- Идентификатор сети:
Идентификатор сети или пункт назначения, соответствующий маршруту. - Маска подсети:
Маска, которая используется для сопоставления IP-адреса назначения с идентификатором сети. - Next Hop:
IP-адрес, на который пересылается пакет. - Исходящий интерфейс:
Исходящий интерфейс, пакет должен выйти, чтобы достичь сети назначения. - Метрика:
Обычно метрика используется для обозначения минимального количества переходов (пересекаемых маршрутизаторов) для идентификатора сети.
Записи таблицы маршрутизации могут использоваться для хранения следующих типов маршрутов:
- Сетевые идентификаторы с прямым подключением
- идентификаторов удаленной сети
- хост-маршрутов
- Маршрут по умолчанию
- Пункт назначения
Когда маршрутизатор получает пакет, он проверяет IP-адрес назначения и просматривает свою таблицу маршрутизации , чтобы выяснить, какой интерфейсный пакет будет отправлен.
Как заполняются таблицы маршрутизации?
Есть способы сохранить таблицу маршрутизации:
Эти таблицы маршрутизации можно поддерживать вручную или динамически.В динамической маршрутизации устройства автоматически создают и поддерживают свои таблицы маршрутизации, используя протоколы маршрутизации для обмена информацией об окружающей топологии сети. Таблицы динамической маршрутизации позволяют устройствам «слушать» сеть и реагировать на такие события, как сбои устройств и перегрузка сети. Таблицы для статических сетевых устройств не изменяются, если администратор сети не изменит их вручную.
Процесс определения маршрута (поиск идентификатора подсети с помощью таблицы маршрутизации):
Считайте, что сеть разбита на 4 подсети, как показано на рисунке выше.IP-адреса четырех подсетей:
200.1.2.0 (подсеть а) 200.1.2.64 (Подсеть b) 200.1.2.128 (Подсеть c) 200.1.2.192 (Подсеть d)
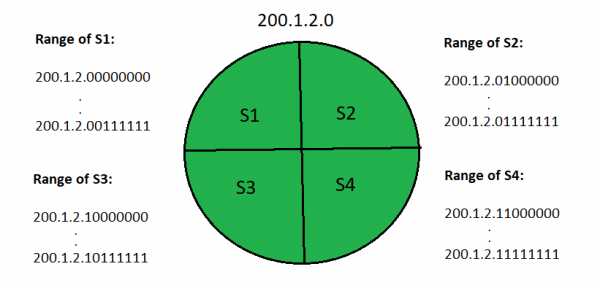
Тогда Таблица маршрутизации , поддерживаемая внутренним маршрутизатором, выглядит так:
| Пункт назначения | Маска подсети | Интерфейс |
|---|---|---|
| 200.1.2.0 | 255.255.255.192 | a |
| 200.1.2.64 | 255.255.255.192 | б |
| 200.1.2.128 | 255.255.255.192 | с |
| 200.1.2.192 | 255.255.255.192 | д |
| По умолчанию | 0,0.0.0 | e |
Чтобы найти свою правильную подсеть (идентификатор подсети), маршрутизатор выполняет побитовое И для IP-адреса назначения, указанного в пакете данных, и всех масок подсети одну за другой.
- Если обнаружено только одно совпадение, маршрутизатор пересылает пакет данных на соответствующий интерфейс.
- Если найдено более одного совпадения, маршрутизатор пересылает пакет данных на интерфейс, соответствующий самой длинной маске подсети.
- Если совпадений нет, маршрутизатор пересылает пакет данных на интерфейс, соответствующий записи по умолчанию.
Пример-1: GATE-CS-2004 | Вопрос 55
Пример-2: GATE IT 2006 | Вопрос 63
Обратите внимание на , что таблицы маршрутизации не относятся к устройствам Cisco.Даже в вашей операционной системе Windows есть таблица маршрутизации, которую можно отобразить с помощью команды печати маршрута
.Вниманию читателя! Не переставай учиться сейчас. Ознакомьтесь со всеми важными концепциями теории CS для собеседований SDE с курсом CS Theory Course по доступной для студентов цене и будьте готовы к отрасли.
.Что такое маршрутизация на стороне клиента и как она используется?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Рекламная